DataBase Design and SQL: the Blueprint for Data Architecture
Introduction: Your Data’s Foundation Story
Think of database design like designing the blueprint for a city. Just as urban planners must consider traffic flow, zoning, infrastructure, and future growth, database architects must thoughtfully organize data structures, relationships, and access patterns to support both current needs and future scaling requirements.
A well-defined schema ensures development teams sync up with users’ and stakeholders’ needs and expectations, creating the foundation upon which every data-driven application is built. Whether you’re building a simple web application or a complex machine learning pipeline, your database schema determines everything from query performance to data integrity.
Understanding Database Schemas: The Architectural Foundation
What Is a Database Schema?
A database schema defines the structure of a database, including tables, fields, relationships, and constraints. It is a blueprint for organizing and storing data, ensuring data integrity and consistency.
Imagine your schema as the DNA of your database - it contains the genetic instructions for how your data will be organized, how different pieces relate to each other, and what rules govern data storage and retrieval.
The Schema Spectrum: Choosing Your Data Architecture
Knowing about different types of database schemas is key to picking the right one for your data storage and retrieval needs. Let’s explore the architectural patterns available:
Relational Model: The Time-Tested Foundation
The relational model is a type of database schema that efficiently organizes data into tables with rows and columns, ensuring optimal storage. Tables establish relationships through keys to uphold data integrity.
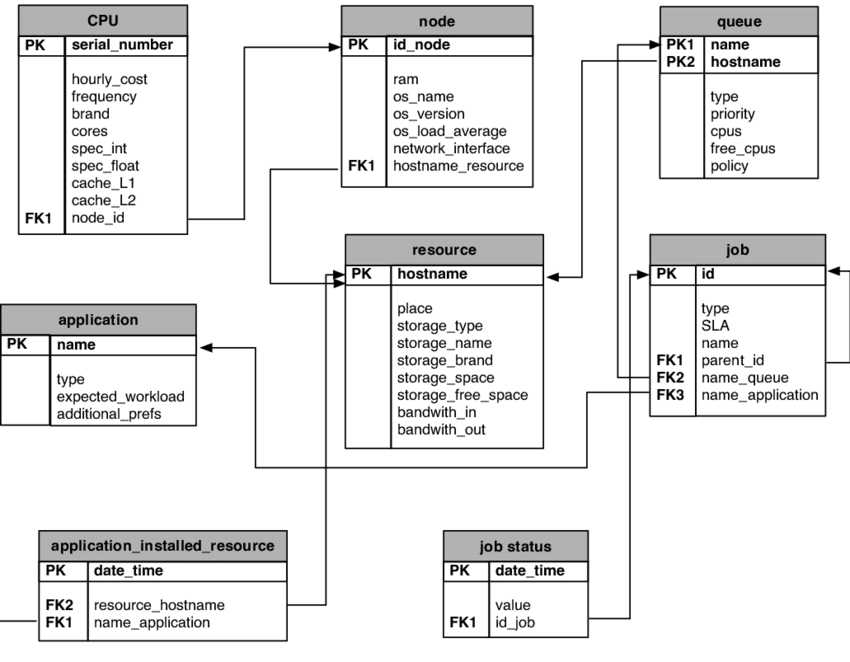
-- Example: E-commerce Database Schema
CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY,
email VARCHAR(255) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INTEGER REFERENCES customers(customer_id),
order_total DECIMAL(10,2) NOT NULL,
order_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE order_items (
item_id SERIAL PRIMARY KEY,
order_id INTEGER REFERENCES orders(order_id),
product_id INTEGER NOT NULL,
quantity INTEGER NOT NULL,
unit_price DECIMAL(10,2) NOT NULL
);
Why Choose Relational?
- ACID Compliance: Transactions are atomic, consistent, isolated, and durable
- Complex Queries: SQL’s expressive power enables sophisticated data analysis
- Data Integrity: Foreign key constraints prevent orphaned records
- Mature Ecosystem: Decades of tooling, optimization, and expertise
Star Schema: Analytics Optimized
Star schema is a data modeling technique that consists of a central fact table connected to multiple dimension tables. This design simplifies data analysis queries by providing a clear database structure for storing and retrieving information.
-- Analytics-focused schema design
-- Fact table (center of the star)
CREATE TABLE sales_fact (
sale_id BIGSERIAL PRIMARY KEY,
customer_key INTEGER,
product_key INTEGER,
time_key INTEGER,
store_key INTEGER,
-- Measures (the actual business metrics)
revenue DECIMAL(10,2),
quantity_sold INTEGER,
discount_amount DECIMAL(10,2)
);
-- Dimension tables (points of the star)
CREATE TABLE customer_dim (
customer_key SERIAL PRIMARY KEY,
customer_name VARCHAR(255),
age_group VARCHAR(50),
geographic_region VARCHAR(100)
);
CREATE TABLE time_dim (
time_key SERIAL PRIMARY KEY,
date_actual DATE,
day_of_week VARCHAR(10),
month_name VARCHAR(15),
quarter VARCHAR(5),
fiscal_year INTEGER
);
Star Schema Benefits:
- Query Performance: Single joins from fact to dimensions
- Business User Friendly: Matches how business people think about data
- Aggregation Optimized: Perfect for reporting and analytics
Snowflake Schema: Normalized Dimensions
The Snowflake schema is a robust data modeling strategy, strategically arranging data across interconnected tables to slash redundancy and bolster query efficiency.
-- Normalized dimension hierarchy
CREATE TABLE product_category (
category_id SERIAL PRIMARY KEY,
category_name VARCHAR(100),
parent_category_id INTEGER REFERENCES product_category(category_id)
);
CREATE TABLE product_dim (
product_key SERIAL PRIMARY KEY,
product_name VARCHAR(255),
category_id INTEGER REFERENCES product_category(category_id),
brand_name VARCHAR(100)
);
The Database Design Process: A Strategic Approach

Step 1: Define Your Data Model
Begin this process by identifying the entities, such as customers or products, their attributes like names or quantities, and the relationships connecting them.
Domain Modeling Approach:
# Conceptual model before database implementation
class Customer:
def __init__(self, email: str, name: str):
self.customer_id = None
self.email = email
self.name = name
self.orders = [] # One-to-many relationship
class Order:
def __init__(self, customer_id: int, total: decimal):
self.order_id = None
self.customer_id = customer_id
self.total = total
self.items = [] # One-to-many relationship
This conceptual model directly translates to your database schema, ensuring alignment between your code and data architecture.
Step 2: Choose the Right Database Management System
Your DBMS is the backbone of your project, dictating how your data flows and scales. Consider these factors:
| Use Case | Recommended DBMS | SQL Flavor | Why |
|---|---|---|---|
| Web Applications | PostgreSQL | Standard SQL | ACID compliance, JSON support, extensibility |
| Analytics | Amazon Redshift | PostgreSQL-compatible | Column storage, MPP architecture |
| High Transactions | MySQL | MySQL dialect | High performance, proven scalability |
| Enterprise | SQL Server | T-SQL | Integration with Microsoft ecosystem |
| Document Storage | MongoDB | MongoDB Query Language | Schema flexibility, JSON-native |
Step 3: Implement Normalization Strategically
This technique helps reduce redundancy and optimize data storage, ensuring efficient organization and preventing data duplication or inconsistent updates.
Normalization Forms in Practice:
-- First Normal Form (1NF): Atomic values
-- ❌ Violates 1NF
CREATE TABLE customers_bad (
customer_id INTEGER,
name VARCHAR(255),
phone_numbers TEXT -- "555-1234, 555-5678, 555-9999"
);
-- ✅ Follows 1NF
CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY,
name VARCHAR(255)
);
CREATE TABLE customer_phones (
phone_id SERIAL PRIMARY KEY,
customer_id INTEGER REFERENCES customers(customer_id),
phone_number VARCHAR(15)
);
-- Second Normal Form (2NF): Remove partial dependencies
-- ✅ Properly normalized order system
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
customer_id INTEGER REFERENCES customers(customer_id),
order_date DATE
);
CREATE TABLE products (
product_id SERIAL PRIMARY KEY,
product_name VARCHAR(255),
unit_price DECIMAL(10,2)
);
CREATE TABLE order_items (
order_id INTEGER REFERENCES orders(order_id),
product_id INTEGER REFERENCES products(product_id),
quantity INTEGER,
PRIMARY KEY (order_id, product_id)
);
SQL: The Language of Data
CRUD Operations: The Foundation of Data Interaction
Before diving into advanced SQL concepts, it’s essential to understand CRUD operations - the four fundamental operations that form the backbone of all database interactions:
CRUD stands for Create, Read, Update, and Delete - these operations map directly to SQL commands and represent the basic ways applications interact with data.
The Four Pillars of Data Operations
-- CREATE: Adding new data
INSERT INTO customers (name, email, created_at)
VALUES ('Alice Johnson', 'alice@example.com', CURRENT_TIMESTAMP);
-- READ: Retrieving existing data
SELECT customer_id, name, email
FROM customers
WHERE created_at >= '2024-01-01';
-- UPDATE: Modifying existing data
UPDATE customers
SET email = 'alice.johnson@newdomain.com'
WHERE customer_id = 1;
-- DELETE: Removing data
DELETE FROM customers
WHERE created_at < '2020-01-01' AND last_login IS NULL;
CRUD in Application Architecture
# Modern application layer implementing CRUD
class CustomerService:
def create_customer(self, customer_data):
"""CREATE operation"""
return self.db.execute(
"INSERT INTO customers (name, email) VALUES (%s, %s) RETURNING customer_id",
(customer_data['name'], customer_data['email'])
)
def get_customer(self, customer_id):
"""READ operation"""
return self.db.fetch_one(
"SELECT * FROM customers WHERE customer_id = %s",
(customer_id,)
)
def update_customer(self, customer_id, updates):
"""UPDATE operation"""
return self.db.execute(
"UPDATE customers SET email = %s WHERE customer_id = %s",
(updates['email'], customer_id)
)
def delete_customer(self, customer_id):
"""DELETE operation"""
return self.db.execute(
"DELETE FROM customers WHERE customer_id = %s",
(customer_id,)
)
Beyond Basic CRUD: Advanced Patterns
As applications grow in complexity, basic CRUD evolves into more sophisticated patterns:
-- Bulk operations for performance
INSERT INTO customers (name, email)
SELECT name, email FROM staging_customers
WHERE validation_status = 'approved';
-- Conditional updates (UPSERT)
INSERT INTO customer_preferences (customer_id, preference_key, preference_value)
VALUES (1, 'newsletter', 'weekly')
ON CONFLICT (customer_id, preference_key)
DO UPDATE SET preference_value = EXCLUDED.preference_value;
-- Soft deletes for data preservation
UPDATE customers
SET deleted_at = CURRENT_TIMESTAMP, is_active = false
WHERE customer_id = 1;
SQL as a Declarative Language
Unlike procedural programming languages, SQL is declarative - you describe what you want, not how to get it:
-- Declarative: Describe the result you want
SELECT
c.name,
COUNT(o.order_id) as order_count,
SUM(o.total) as lifetime_value
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
WHERE c.created_at >= '2024-01-01'
GROUP BY c.customer_id, c.name
HAVING COUNT(o.order_id) > 0
ORDER BY lifetime_value DESC;
Advanced SQL Patterns for Modern Applications
Window Functions for Analytics
-- Customer ranking and running totals
SELECT
customer_id,
order_date,
order_total,
-- Running total of orders for each customer
SUM(order_total) OVER (
PARTITION BY customer_id
ORDER BY order_date
ROWS UNBOUNDED PRECEDING
) as running_total,
-- Rank customers by order value
DENSE_RANK() OVER (
ORDER BY order_total DESC
) as value_rank
FROM orders
WHERE order_date >= '2024-01-01';
CTEs for Complex Logic
-- Multi-step analysis using Common Table Expressions
WITH monthly_sales AS (
SELECT
DATE_TRUNC('month', order_date) as month,
SUM(order_total) as monthly_revenue
FROM orders
GROUP BY DATE_TRUNC('month', order_date)
),
sales_growth AS (
SELECT
month,
monthly_revenue,
LAG(monthly_revenue) OVER (ORDER BY month) as prev_month_revenue,
(monthly_revenue - LAG(monthly_revenue) OVER (ORDER BY month)) /
LAG(monthly_revenue) OVER (ORDER BY month) * 100 as growth_rate
FROM monthly_sales
)
SELECT
month,
monthly_revenue,
ROUND(growth_rate, 2) as growth_percentage
FROM sales_growth
WHERE month >= '2024-01-01'
ORDER BY month;
Best Practices for Database Excellence
1. Establish Strong Foundations
Primary and foreign keys serve as the foundation for your database organization. Exclusive identifiers within database tables and primary keys guarantee clear-cut distinctions for each row.
-- Strong foundational constraints
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
email VARCHAR(255) UNIQUE NOT NULL,
username VARCHAR(50) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-- Validation constraints
CONSTRAINT valid_email CHECK (email ~* '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$'),
CONSTRAINT valid_username CHECK (length(username) >= 3)
);
2. Strategic Indexing
Key columns should be indexed to enhance query performance and ensure efficient database operation, particularly as it expands.
-- Performance-focused indexing
CREATE INDEX idx_orders_customer_date ON orders(customer_id, order_date);
CREATE INDEX idx_products_category ON products(category_id) WHERE active = true;
-- Partial index for common queries
CREATE INDEX idx_high_value_orders ON orders(order_date)
WHERE order_total > 1000;
3. Descriptive Naming Conventions
Well-defined naming conventions serve as guideposts within your database, promoting clarity and facilitating comprehension.
-- Clear, descriptive naming
CREATE TABLE customer_subscription_plans (
subscription_id SERIAL PRIMARY KEY,
customer_id INTEGER REFERENCES customers(customer_id),
plan_name VARCHAR(100) NOT NULL,
monthly_price DECIMAL(10,2) NOT NULL,
billing_cycle_start_date DATE NOT NULL,
is_active BOOLEAN DEFAULT true
);
Modern Database Architectures
Polyglot Persistence
Modern applications often use multiple database technologies:
# Example: Multi-database application architecture
class DataLayer:
def __init__(self):
self.postgres = PostgreSQLConnection() # Transactional data
self.redis = RedisConnection() # Caching layer
self.elasticsearch = ESConnection() # Search functionality
def create_user(self, user_data):
# Primary storage in PostgreSQL
user = self.postgres.insert_user(user_data)
# Cache in Redis
self.redis.cache_user(user.id, user_data)
# Index in Elasticsearch for search
self.elasticsearch.index_user(user)
Event Sourcing with SQL
-- Event sourcing pattern for audit trails
CREATE TABLE events (
event_id SERIAL PRIMARY KEY,
aggregate_id UUID NOT NULL,
event_type VARCHAR(100) NOT NULL,
event_data JSONB NOT NULL,
event_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-- Enable efficient querying
INDEX (aggregate_id, event_timestamp),
INDEX (event_type, event_timestamp)
);
-- Materialized view for current state
CREATE MATERIALIZED VIEW customer_current_state AS
SELECT
aggregate_id as customer_id,
(event_data->>'name') as current_name,
(event_data->>'email') as current_email,
MAX(event_timestamp) as last_updated
FROM events
WHERE event_type IN ('customer_created', 'customer_updated')
GROUP BY aggregate_id, event_data->>'name', event_data->>'email';
The Future of Database Design
Considerations for Modern Applications
API-First Design:
-- Design with API consumption in mind
CREATE VIEW customer_api_view AS
SELECT
customer_id,
name,
email,
created_at,
(
SELECT COUNT(*)
FROM orders
WHERE orders.customer_id = customers.customer_id
) as order_count,
(
SELECT SUM(order_total)
FROM orders
WHERE orders.customer_id = customers.customer_id
) as lifetime_value
FROM customers;
Real-time Analytics:
-- Streaming-friendly schema design
CREATE TABLE events_stream (
event_id BIGSERIAL PRIMARY KEY,
user_id INTEGER,
event_name VARCHAR(100),
event_properties JSONB,
event_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-- Partitioning for performance
PARTITION BY RANGE (event_timestamp)
);
Conclusion: Building Data Architecture That Scales
Designing a robust database schema is essential for ensuring that your project data management aligns with the stakeholders’ requirements and expectations. The key is understanding that database design is not just about storing data - it’s about creating a foundation that enables your application to grow, perform, and adapt to changing business needs.
Key Takeaways:
- Start with Domain Modeling: Understand your business entities before diving into implementation
- Choose the Right Tool: Different use cases demand different database architectures
- Design for Evolution: Your schema should accommodate future requirements
- Performance from the Start: Index strategically and design queries alongside schema
- Documentation Matters: Comprehensive documentation, including a detailed data dictionary, is like a guidebook for developers, administrators, and other stakeholders
Remember, a well-designed database schema is like a well-architected building - it provides the structural integrity that allows everything built on top of it to flourish. Whether you’re working with traditional SQL databases or exploring modern alternatives, the principles of thoughtful design, clear relationships, and performance optimization remain constant.
The future belongs to developers who understand that data architecture is not just about storage - it’s about creating the foundation for intelligent, scalable, and resilient applications that can adapt and thrive in an ever-changing technological landscape.