Table of Contents
- Introduction
- The Pre-Attention Era
- The Attention Revolution
- The Post-Attention Era
- The Bigger Picture
- Conclusion and Future Directions
Introduction
When Charles Darwin embarked on his five-year journey aboard the HMS Beagle in 1831, he couldn’t have anticipated how his theory of evolution would one day serve as an apt metaphor for understanding the development of artificial intelligence. Just as biological organisms have evolved from simple structures to complex beings through natural selection, language models have undergone their own rapid evolution—from basic word-counting mechanisms to sophisticated systems capable of understanding and generating human language with remarkable proficiency.
In this blog post, we’ll explore the evolutionary journey of Large Language Models (LLMs), tracing their development through three distinct eras: the pre-attention era, the attention revolution initiated by the “Attention is All You Need” paper in 2017, and the current post-attention era characterized by scaling, emergence, and multitask capabilities.
The Pre-Attention Era
Early Word Representations
The earliest approaches to Natural Language Processing (NLP) faced a fundamental challenge: how to represent words in a way that computers could process them. The initial solutions were remarkably simple:
- One-hot encoding: Each word is represented as a vector of zeros with a single “1” at the position corresponding to that word in the vocabulary.
- Bag-of-words: Text is represented as a multiset of its words, disregarding grammar and word order.
- TF-IDF (Term Frequency-Inverse Document Frequency): Words are weighted by how frequently they appear in a document relative to how commonly they appear across all documents.
These representations, while computationally manageable, were extremely limited in their ability to capture the semantic relationships between words.
# Simple one-hot encoding example
vocabulary = {"cat": 0, "dog": 1, "house": 2, "tree": 3}
word = "cat"
one_hot = [0] * len(vocabulary)
one_hot[vocabulary[word]] = 1
print(one_hot) # [1, 0, 0, 0]
The challenges of tokenization—determining what constitutes a “word”—were also significant. Should contractions like “I’m” be treated as one token or two (“I” and “am”)? What about hyphenated words, abbreviations, or proper nouns like “Hewlett-Packard”?
Static Word Embeddings
A breakthrough came with the development of distributed word representations, commonly known as word embeddings. Instead of sparse, high-dimensional one-hot vectors, words were now represented as dense, lower-dimensional vectors where the relative positions of words in the vector space encoded semantic relationships.
Models like Word2vec (2013), GloVe (2014), and FastText (2016) revolutionized the field by enabling remarkable semantic operations:
vector["King"] - vector["Man"] + vector["Woman"] ≈ vector["Queen"]
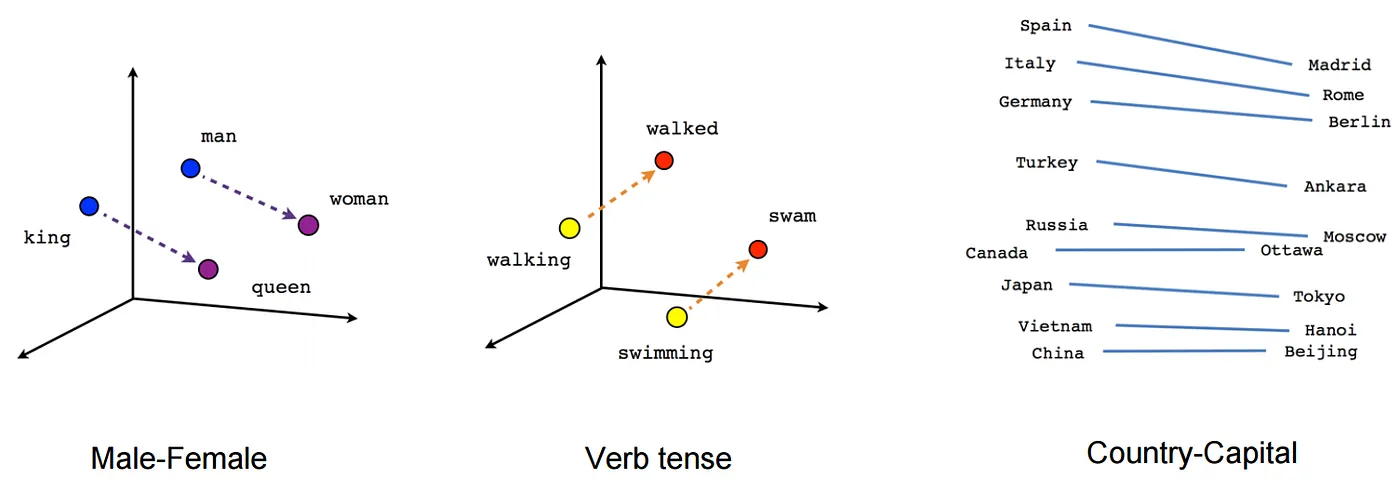 Figure 1: Visualization of word embeddings in a vector space, where semantically similar words cluster together. (Source: Medium, Creative Commons)
Figure 1: Visualization of word embeddings in a vector space, where semantically similar words cluster together. (Source: Medium, Creative Commons)
These static embeddings captured semantic relationships between words, but they had a critical limitation: each word had exactly one vector representation, regardless of context. The word “bank” would have the same representation whether it referred to a financial institution or the side of a river.
Limitations of Pre-Attention Models
Before transformers, sequence modeling relied heavily on Recurrent Neural Networks (RNNs), Long Short-Term Memory networks (LSTMs), and Gated Recurrent Units (GRUs). These architectures processed words sequentially, which came with significant limitations:
- Vanishing gradient problem: As sequences grew longer, the gradient signal diminished, making it difficult to capture long-range dependencies.
- Sequential processing: RNNs couldn’t leverage parallel computing effectively since each step depended on the previous one.
- Fixed context windows: Models like Word2Vec typically used a small context window, limiting their ability to capture broader context.
# Example of a simple RNN in PyTorch
class SimpleRNN(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = torch.nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)
output, hn = self.rnn(x, h0)
out = self.fc(output[:, -1, :])
return out
These limitations set the stage for a revolutionary approach to sequence modeling—one that would overcome these challenges and set the foundation for modern LLMs.
The Attention Revolution
The Transformer Architecture
In 2017, a team at Google published a paper titled “Attention is All You Need,” introducing the Transformer architecture. This seminal work completely revolutionized how sequences are processed in NLP and set the stage for the development of models like BERT, GPT, and their successors.
The Transformer architecture eliminated recurrence entirely, relying instead on attention mechanisms and positional encodings to capture sequential information:
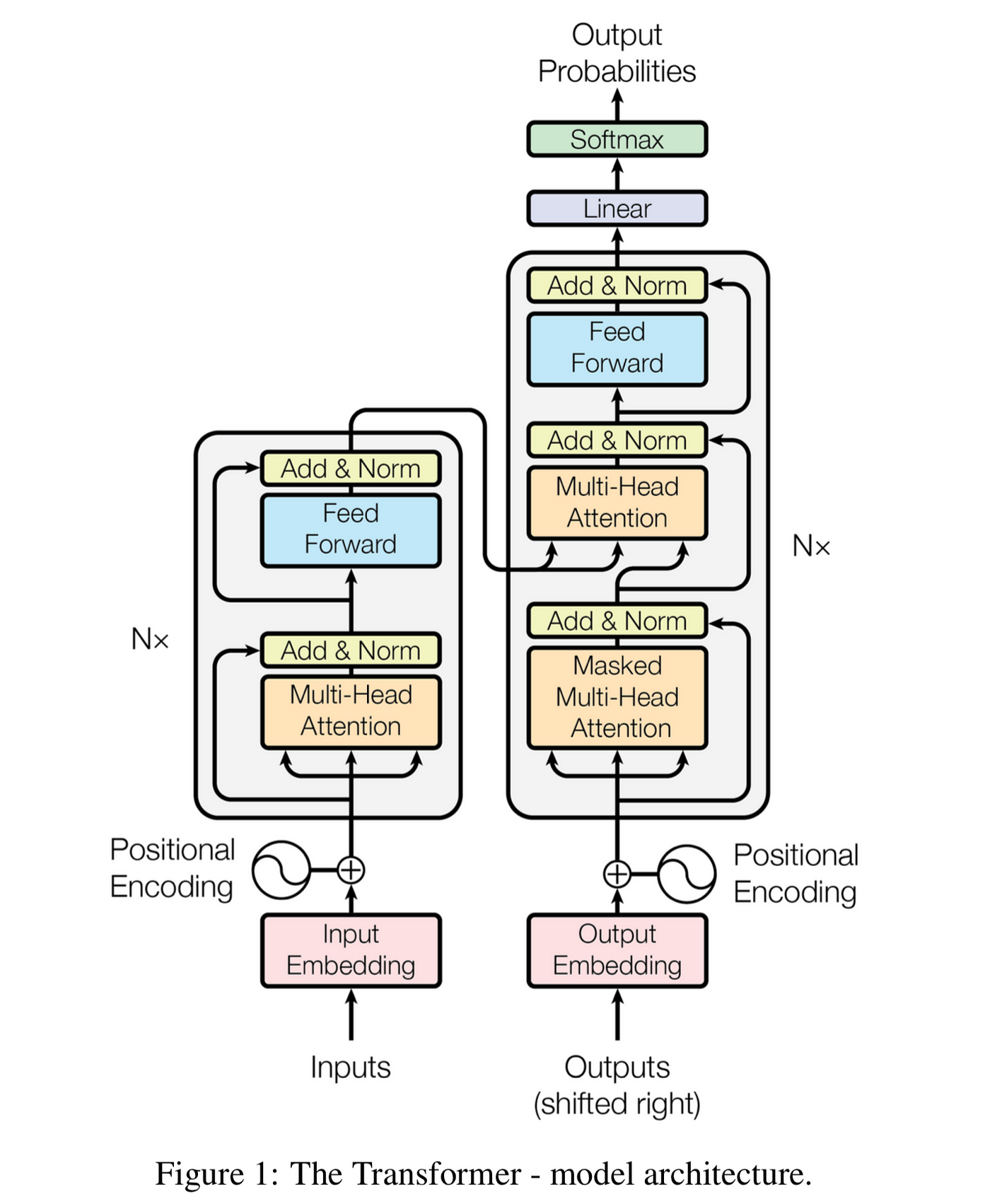 Figure 2: The Transformer architecture consisting of encoder and decoder stacks. (Source: Attention is All You Need paper, adapted visualization)
Figure 2: The Transformer architecture consisting of encoder and decoder stacks. (Source: Attention is All You Need paper, adapted visualization)
Key components of the Transformer include:
- Token Embeddings: Words are converted to numerical vectors
- Positional Encodings: Since the model has no recurrence, position information is explicitly added
- Multi-Head Attention: The core mechanism allowing the model to focus on different parts of the input simultaneously
- Feed-Forward Networks: Apply non-linear transformations to the attention outputs
- Layer Normalization and Residual Connections: Techniques to stabilize training
Self-Attention: The Game Changer
The self-attention mechanism is the true innovation of the Transformer architecture. It allows every token in a sequence to look at every other token and compute a weighted sum of their values, effectively capturing dependencies regardless of their distance in the sequence.
The computation of self-attention involves three projections of each token’s embedding into query (Q), key (K), and value (V) vectors:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
Where d_k is the dimension of the key vectors.
The scaling factor sqrt(d_k) prevents the dot product from growing too large in magnitude as the dimension increases, which would push the softmax function into regions where gradients are very small.
 Figure 3: Illustration of how self-attention works by computing relevance scores between tokens. (Source: Jay Alammar’s blog, used with permission)
Figure 3: Illustration of how self-attention works by computing relevance scores between tokens. (Source: Jay Alammar’s blog, used with permission)
Implementation in PyTorch
Let’s implement a simplified version of the self-attention mechanism in PyTorch to get a better understanding of how it works:
import torch
import torch.nn as nn
import math
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (self.head_dim * heads == embed_size), "Embed size must be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, queries, mask=None):
N = queries.shape[0] # Batch size
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
# Split embedding into heads
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = queries.reshape(N, query_len, self.heads, self.head_dim)
# Transform the projections
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Calculate attention scores
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
# queries shape: (N, query_len, heads, head_dim)
# keys shape: (N, key_len, heads, head_dim)
# energy shape: (N, heads, query_len, key_len)
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# Normalize energy values to get attention weights
attention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=3)
# Apply attention weights to values
out = torch.einsum("nhql,nlhd->nqhd", [attention, values])
# attention shape: (N, heads, query_len, key_len)
# values shape: (N, value_len, heads, head_dim)
# out shape: (N, query_len, heads, head_dim)
out = out.reshape(N, query_len, self.heads * self.head_dim)
out = self.fc_out(out)
return out
This implementation breaks down the core self-attention mechanism into its component parts, showing how the query, key, and value projections are used to compute attention weights, which are then applied to the value vectors to produce the output.
The Post-Attention Era
Scaling Laws and Model Size
One of the most significant findings in recent years is the existence of scaling laws for neural language models. Research by OpenAI and others has demonstrated that model performance improves predictably as a power-law function of model size, dataset size, and computational budget.
These scaling laws suggested that simply making models bigger—with more parameters and trained on more data—would lead to better performance. This insight catalyzed an arms race in model scaling, leading to increasingly massive models:
| Model | Release Date | Parameters |
|---|---|---|
| BERT | 2018 | 340M |
| GPT-2 | 2019 | 1.5B |
| GPT-3 | 2020 | 175B |
| PaLM | 2022 | 540B |
| GPT-4 | 2023 | >1T (est.) |
Data: The New Oil
With model architectures largely standardized around the Transformer, data has become the primary differentiator between competing LLMs. Modern pre-training datasets are enormous and diverse:
- Common Crawl: Petabytes of web data, containing trillions of tokens
- The Pile: 800GB of diverse text from academic papers, books, and more
- RefinedWeb: A filtered subset of Common Crawl with over 5 trillion tokens
- Specialized corpora: Wikipedia, GitHub code repositories, books, and academic papers
The quality of data preprocessing has become as important as quantity:
# Simplified example of modern data preprocessing pipeline
def preprocess_web_document(doc):
# Remove boilerplate content
doc = remove_html_boilerplate(doc)
# Deduplicate at document and paragraph level
doc = deduplicate_text(doc)
# Filter for quality
quality_score = compute_quality_score(doc)
if quality_score < QUALITY_THRESHOLD:
return None
# Filter for safety
safety_score = compute_safety_score(doc)
if safety_score < SAFETY_THRESHOLD:
return None
# Tokenize for model input
tokens = tokenizer.encode(doc)
return tokens
Emergent Abilities
Perhaps the most fascinating aspect of the post-attention era is the discovery of emergent abilities in LLMs. As models scale up, they develop capabilities that were not explicitly trained for and that smaller models do not exhibit, even qualitatively.
Examples of emergent abilities include:
- Few-shot learning: The ability to learn new tasks from just a few examples
- Chain-of-thought reasoning: The capacity to break down complex problems into steps
- Code generation: Synthesizing functional code from natural language descriptions
- Multimodal understanding: Interpreting and generating content across different modalities
These emergent abilities suggest that scaling is not just about incremental improvements but can lead to qualitative shifts in model capabilities.

Figure 4: Emergin abilities diagram
The Bigger Picture
Computational Requirements
The computational resources required to train state-of-the-art LLMs are staggering:
- GPT-3 (175B parameters): Estimated training cost of $4-12 million
- PaLM (540B parameters): Trained using 6,144 TPU v4 chips
- GPT-4: Likely required thousands of high-end GPUs/TPUs running for months
Let’s break down a simplified calculation for estimating training costs:
# Simplified training cost estimation
def estimate_training_cost(
model_params_billions,
tokens_trillions,
gpu_type="A100",
gpu_cost_per_hour=5.0
):
# Estimates based on published scaling laws and industry benchmarks
if gpu_type == "A100":
tokens_per_gpu_hour = 150000 * model_params_billions**(-0.7)
elif gpu_type == "H100":
tokens_per_gpu_hour = 300000 * model_params_billions**(-0.7)
total_tokens = tokens_trillions * 1e12
total_gpu_hours = total_tokens / tokens_per_gpu_hour
# Assume optimal parallelization
optimal_gpu_count = min(model_params_billions * 8, 10000)
training_hours = total_gpu_hours / optimal_gpu_count
total_cost = total_gpu_hours * gpu_cost_per_hour
return {
"GPU Hours": total_gpu_hours,
"Training Duration (days)": training_hours / 24,
"Estimated Cost": f"${total_cost:,.2f}"
}
# Example: Training a 100B parameter model on 1.5T tokens
print(estimate_training_cost(100, 1.5))
The massive computational requirements have significant implications for the field:
- Concentration of power: Only well-funded companies can afford to train the largest models
- Research challenges: Academic labs struggle to compete without industry-scale resources
- Democratization efforts: Smaller, more efficient models like BLOOM and LLaMA aim to broaden access
Environmental Impact
The environmental footprint of training large language models has raised concerns about sustainability:
- GPT-3 training: Estimated 552 tons of CO2 emissions (equivalent to 123 passenger vehicles driven for one year)
- Massive data centers require extensive cooling and electricity
The AI community has responded with efforts to improve efficiency:
- Carbon tracking: Tools like ML CO2 Impact to measure emissions
- Efficient architectures: Research into models that achieve strong performance with fewer parameters
- Specialized hardware: Chips designed specifically for machine learning workloads
Multitask Capabilities
In the post-attention era, the distinction between task-specific models has largely disappeared. Modern LLMs are generalist systems that can perform a wide range of tasks without task-specific architectures:
- Text classification
- Generation and summarization
- Translation
- Question answering
- Reasoning
- Code generation
This shift toward unified models represents a significant departure from the pre-attention paradigm of specialized models for specific tasks.
Conclusion and Future Directions
The evolution of language models mirrors Darwin’s theory in many ways: we’ve seen incremental improvements punctuated by revolutionary jumps, with the most adaptive approaches surviving and propagating through the field. From simple word-counting methods to attention-based architectures capable of emergent reasoning, the progress has been remarkable.
As we look to the future, several trends and challenges emerge:
-
Efficiency over scale: After years focused on scaling up, researchers are now exploring ways to achieve similar capabilities with smaller, more efficient models.
-
Multimodal integration: The integration of language with other modalities (vision, audio, etc.) is becoming increasingly important, as seen in models like GPT-4V and Gemini.
-
Alignment and safety: As models become more capable, ensuring they’re aligned with human values and safe to deploy becomes critical.
-
Specialization and adaptation: Fine-tuning and adaptation techniques allow general-purpose models to be customized for specific domains and applications.
-
Reasoning capabilities: Enhancing models’ ability to reason step-by-step and solve complex problems remains an active area of research.
The evolutionary journey of language models continues, and just as Darwin could not have predicted the complex organisms that would eventually emerge from natural selection, we cannot fully anticipate what capabilities future language models might develop. What’s certain is that their impact on society, technology, and our understanding of intelligence will be profound.
As software engineers and researchers in this field, we stand at a unique moment in computational history—witnessing and participating in this evolution firsthand.